Engine-Based Compilation
We have developed a C++ code generator for BIP programs that supports the full BIP syntax. The generic part of the generated code (i.e. that is independent from the input model) is the BIP Execution Engine.
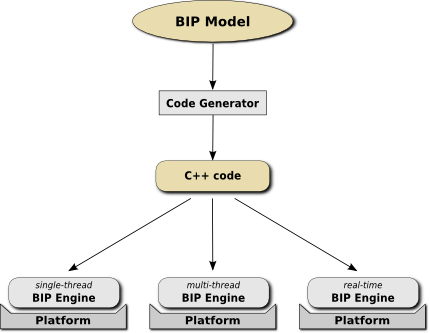
The BIP Engine computes execution traces that meet the semantics of BIP. It can be used as a runtime for the execution of BIP models, as a debugger, as a simulator (single execution trace), or as an explorer (all execution traces specified by the model). The following BIP Engines are currently available:
- The Single-Thread Engine is based on a single thread execution of the components.
- The Multi-Thread Engine uses several threads for the execution of components. This improves performances on multi-core architectures.
- The Real-Time Engine can be used for the real-time execution of BIP models that involve real-time constraints (i.e. components behavior are timed automata). It is currently based on a single-thread execution, and assume the presence of a real-time clock on the target platform.
Send/Receive BIP Compilation
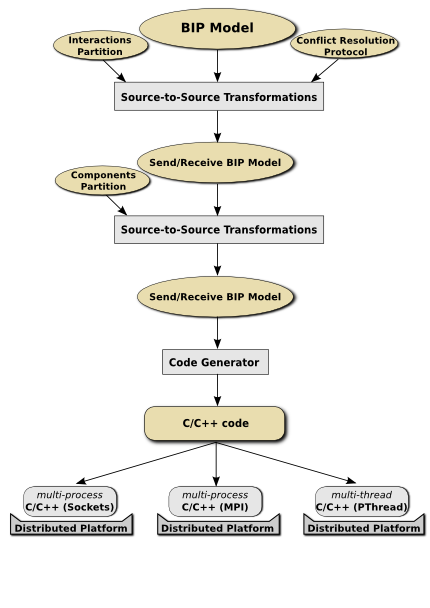
To generate distributed implementations from BIP models it is necessary to transform these models into Send/Receive BIP models, directly implementable on distributed execution platforms. The transformation consists of:
- breaking atomicity of actions in atomic components by replacing strong synchronizations with asynchronous Send/Receive interactions;
- inserting several distributed Engines that coordinate execution of interactions according to a user-defined partition;
- augmenting the model with a distributed algorithm for handling conflicts between distributed Engines.
Then, from Send/Receive BIP model and a partition of atomic components it is possible to merge some components in order to obtain a new Send/Receive model.
Finally, from the obtained Send/Receive BIP model and a mapping of atomic components into processing elements of a platform it is possible to generate efficient C/C++ using either socket, MPI or shared memory for implementing Send/Receive primitives.