Non, il ne manque pas de s à fini car c'est le nombre qui est fini.
Motivation
Depuis la définition en 1950 des AEFs par S.C.Kleene, C.Shannon & J.Mc.Carty,
les utilisations des automates ne cessent de se multiplier.
Programmer sans compter
Le pouvoir d'expression des automates est limité : ils ne peuvent pas compter (ou seulement de manière bornée).
En revanche ils offrent un moyen simple de programmer et on leur trouve de nouveaux usages chaque année :
recherche d'un mot dans un texte : complexité en \(O(m^3 + t)\) où \(m\) est la taille du mot et \(t\) la taille du texte
tandis que l'algorithme naïf est en \(O(m \times t)\).
compilation : analyse lexicale par des AEF et analyse syntaxique par des AUP (automates à une pile)
conception de circuits, de protocoles, de menu de navigation, de digicode, de politque de sécurité, de processus administratifs, ...
programmation de comportements simples : électro-ménager, domotique, bots de jeux vidéo
Vous êtes cernés : les automates sont partout.
Non-déterminisme et minimalité
Pour nous les machines, les automates sont nos ancètres et nos philosophes antiques:
Ils ont résolu la grande question du non-déterminisme.
Les AEFs sont la concrétisation du rêve de l'informaticien :
un automate non-déterministe est concis, facile à concevoir mais inefficace
à cause des multiples chemins d'exécution possibles.
L'algorithme de déterminisation produit un automate déterministe équivalent :
peu lisible, très simple à exécuter, de manière efficace.
L'algorithme de minimisation en donne une version équivalente plus compacte
La recherche en informatique vise à étendre ce rêve à un modèle de programmation plus riche
que les automates à nombre d'états fini (AEF).
On sait qu'il n'existe pas d'algorithme de déterminisation pour les automates à piles (AUP).
On explore donc le spectre entre AEF et AUP.
Les automates d'arbre suscitent actuellement un vif intérêt.
Les automates d'arbre ce n'est pas que du green washing.
Ils sont très puissants : ils permettent d'analyser des langages à balises tels que XML, HTML.
Représentation finie d'un ensemble infini de données
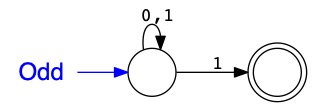
L'automate \(Odd\) reconnaît les mots binaires qui représentent des nombres impairs.
C'est une représentation finie (et compacte) de l'ensemble infini
\(\{1,3,5,...\}\).
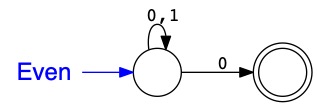
L'automate \(Even\) reconnaît les mots binaires qui représentent des nombres pairs.
C'est une représentation finie (et compacte) de l'ensemble infini
\(\{0,2,4,...\}\).
L'opérateur \(\oplus\) [B.Boigelot & P.Wolper, 2002] prend en paramètre deux automates représentant des ensembles
et calcule en un temps fini (et court) toutes les sommes possibles d'un entier pris dans l'ensemble
représenté par le premier automate et d'un entier pris dans l'ensemble représenté par le second automate.
\(
Odd \oplus Even = \{1+0,1+2,1+4,...,3+0,3+2,3+4,...,5+0,5+2,5+4,...\}
\)
Mais au lieu d'énumérer l'infinité des valeurs possibles de l'ensemble,
B&W donne le résultat sous la forme d'un automate.
Malgré leur simplicité les automates font mieux que l'ordinateur quantique :
l'opérateur \(\oplus\) effectue une infinité d'opérations en parallèle
et sur une machine standard.
L'algorithme \(\oplus\) donnent les résutlats suivants :
\(Even \oplus Even = Even\)
\(Odd \oplus Even = Odd\)
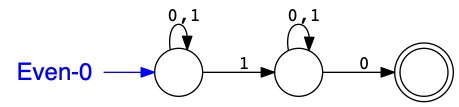
\(Odd \oplus Odd = \textit{Even-0}\)
Nous apprendrons dans ce cours à reconnaître les ensembles représentés par les AEFs.
L'automate \(\textit{Even-0}\) reconnaît l'ensemble des entiers pairs privé de 0.
Notez que l'opérateur \(\oplus\) donne une façon de vérifier/démontrer par le calcul
les règles mathématiques apprises en \(6^{eme}\).
On découvre ici une nouvelle branche des mathématiques qui fait débat actuellement :
Est-ce qu'un calcul fait par ordinateur peut-être considéré comme une preuve ?
Vous avez là les grands thèmes que nous aborderons dans ce chapitre
opérations ensemblistes \(\leftrightarrow\) opérations sur les automates
déterminisation
minimisation
applications et limitations
[B.Boigelot & P.Wolper, 2002]Representing Arithmetic Constraints with Automata: An Overview,
in Proceedings of the 18h International Conference on Logic Programming,
volume 2401 of Lecture Notes in Computer Science, page 1-19.
Alphabet, mot, langage : définitions et opérations
Symbole et Alphabet
L'alphabet, noté \(\Sigma\), est un ensemble de symboles.
Exemple
on utilisera souvent l'alphabet, \(\Sigma = \{a,b\}\).
Opérations sur les mots
Un mot sur est une séquence finie de symboles pris dans l'alphabet.
C'est l'équivalent d'une chaîne de caractères.
Exemple
\(a,b,aa,ab,ba,bb,aaa, aab, ...\) sont des mots
qui correspondent aux chaînes de caractères
"a","b","aa","ab","ba","bb","aaa","aab".
Le mot "" qui n'a aucun symbole est appelé le mot muet
et on le trouve souvent noté \(\epsilon\) dans la littérature.
L'opérateur de concaténation de mots
Il est noté « . » et permet de coller deux mots : \(ab.ba = abba = a.b.b.a\)
\(\epsilon\) est l'élément neutre de la concaténation de mots :
\(\epsilon.a=a=a.\epsilon\).
Itéré d'un mot
\(\omega^n\) est la concaténation de \(n\) copies du mot \(\omega\).
Exemple
\(\omega^0\) est donc la concaténation de 0 copie du mot \(\omega\)
c'est donc l'élément neutre de « . » ie. \(\omega^0=\epsilon\).
\(a^3 = a.a.a = aaa\)
Longueur d'un mot
La longueur d'un mot, noté \(|\omega|\), est le nombre de symboles de \(\Sigma\)
dans la séquence.
C'est la longueur de la chaîne de caractères.
\(|\omega_1.\omega_2| = |\omega_1| + |\omega_2|\)
\(|\epsilon|=0, |a| = 1, |b|=1, |ab|=2\)
Exemples
les symboles de \(\Sigma\) sont des mots de longueur 1.
\(|a^n| = n\)
Opérations sur les langages
Un langage
est un ensemble de mot.
Exemple
\(\Sigma = \{a,b\}\) est un langage fait de mots de taille 1
\(\{ a^n \mid n\in\mathbb{N\} }\) est l'ensembe infini de tous les mots finis formés uniquement du symbole \(a\).
\(\{\}\) est le langage qui ne contient aucun mot, appelé le langage vide.
à ne pas confondre avec \(\{\epsilon\}\) qui contient un mot.
Puisque les langages sont des ensembles, on peut leur appliquer
tous les opérateurs sur les ensembles :
union : \(L_1 \cup L_2\)
intersection : \(L_1\cap L_2\)
restriction : \(L_1 - L_2\), aussi notée \(L_1 \setminus L_2\)
complémentaire : \(\overline{L}\)
test du vide : \(L \overset{?}{=} \{\}\)
test d'inclusion : \(L_1 \subseteq L_2\)
test d'égalité : \(L_1 = L_2\)
On ajoute quelques opérateurs spécifiques aux langages.
La concaténation du langage \(L_1\) et du langage \(L_2\) est l'ensemble
des mots formés par la concaténation d'un mot \(\omega_1\) pris dans \(L_1\) et d'un mot \(\omega_2\) pris dans \(L_2\).
\(\{\epsilon\}\) est l'élément neutre de la concaténation de langage :
\(\{\epsilon\} \bullet L = L = L \bullet \{\epsilon\}\)
\(\{\}\) est l'élément absorbant de la concaténation de langage :
\(\{\} \bullet L = \{\} = L \bullet \{\}\)
\(L^n\) est la concaténation \((\bullet)\) de \(n\) copies du langage \(L\).
\(L^0\) doit nécessairement être l'élément neutre de l'opérateur \(\bullet\),
ie. \(L^0 = \{\epsilon\}\).
Exemple
\(\Sigma^i\) est l'ensemble des mots de longueur \(i\) écrit sur l'alphabet \(\Sigma\).
L'étoile de Kleene
\(
\begin{array}{rcccccccccc}
L^* &=& \bigcup_{i\in\mathbb{N}} &L^i
\\ &=& L^0 &\cup& L^1 &\cup& L^2 &\cup& L^3 &\cup& \ldots
\\ &=& \{\epsilon\} &\cup& L &\cup& L\bullet L &\cup& L \bullet L \bullet L &\cup& \ldots
\end{array}
\)
Exemples
D'après la définition
\(\Sigma^* = \bigcup_{i\in\mathbb{N}} \Sigma^i\) est l'ensemble de tous les mots, de longueur quelconque (finie), que l'on peut former avec les symboles de l'alphabet \(\Sigma\).
\(\{\}^* = \{\epsilon\}\) : on ne peut écrire qu'un seul mot sans symbole.
\(\{\epsilon\}^* = \{\epsilon\}\) : quelle que soit la longueur du mot \(\epsilon^i\) se réduit toujours à \(\epsilon\)
Si le langage \(L\) contient au moins un mot alors \(L^*\) est un ensemble infini.
Remarques
\(L\subseteq\Sigma^*\) signifie donc que les mots de \(L\) sont écrits sur l'alphabet \(\Sigma\)
Le complémentaire de \(L\), noté \(\overline{L}\), est l'ensemble des mots qui ne sont pas dans \(L\).
Puisque \(\Sigma^*\) est l'ensemble de tous les mots possibles,
\(\overline{L} = \Sigma^* - L\).
Représentation d'un langage par un automate
Une régularité est une séquence qui peut être répétée dans les mots du langage
par exemple \(ab, abab, ababab, ...\).
Les langages qui présentent une certaine forme de régularité,
qu'on appelle les langages réguliers,
peuvent être représenté par un automate à nombre d'états fini.
Dans la section suivante on va définir le langage \(\mathcal{L}(A)\) associé à un automate \(A\).
Lorsque \(L=\mathcal{L}(A)\), il est possible de représenter un langage infini \(L\)
par son automate \(A\).
L'intérêt est de manipuler une représentation finie (l'automate \(A\))
plutôt que l'énumération infinie des mots de \(L\).
Le miracle c'est qu'on est capable d'effectuer les opérations sur les langages
(union, intersection, complémentaire, ...) en opérant sur les automates associés.
On effectue ainsi des opérations sur des ensembles infinis en ne manipulant
que des représentations finies (et efficacement en plus).
Comment donc se produit ce miracle de remplacer de l'infini par du fini
sans rien perdre ?
Pour réussir ce tour de force il faut plusieurs ingrédients :
il faut changer le problème forcément infini « stocker tous les mots de \(L\) »
en un problème qui a une réponse finie « l'appartenance d'un mot donné à \(L\) »
On remplace de l'espace mémoire pris par les données brutes (tous les mots) par
le temps d'éxécution d'un processus calculatoire qui effectue le test \(mot\in L\).
On trouve un moyen efficace de tester l'appartenance du \(mot\) à \(L\) :
au lieu de comparer le \(mot\) avec chaque mot de \(L\),
on cherche s'il existe un chemin dans \(A\) qui correspond au \(mot\).
On trouve une régularité qui permet d'encoder les données brutes (tous les mots) sous la forme compacte d'automate.
Chaque régularité du langage se traduit par une boucle dans l'automate,
qui indique le fait qu'on peut répéter autant de fois que la séquence
décrites par la boucle.
\(L\)
\(A\)
espace
énumération des mots
transitions de l'automate
mémoire
infinie
finie
temps
\(\omega\in L\) ?
\(A\) accepte \(\omega\) ?
exécution
finie mais inefficace
efficace \(O(|\omega|)\)
Notez bien que si on demandait d'énumérer les mots de \(L\)
alors le processus serait infini dans le cas de \(L\) comme dans le cas de \(A\).
Pour pouvoir répondre efficacement au problème de « représenter les mots de \(L\) »
vous avez changer de question « décider si un \(mot\) appartient à \(L\) ».
C'est malin.
C'est classique en informatique.
Langage reconnu par un AEF
Représentation graphique au format DOT
L'outil graphviz permet d'afficher
la représentation graphique d'un automate à partir de la description de ses transitions
dans un fichier .dot.
La description ci-dessus produit la représentation graphique suivante :
Le rendu graphique de la description .dot
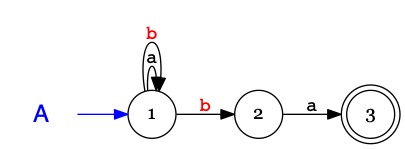
Constituants d'un automate
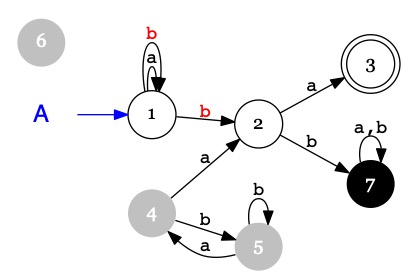
Les états pointés par des flêches bleues depuis le nom de l'automate
sont les états initiaux de l'automate.
Ici, il n'y en a qu'un : \(Init(A) = \{1\}\)
Les états doublement cerclés sont les états accepteurs de l'automate.
Ici, il n'y en a qu'un : \(Acc(A) = \{3\}\).
Les états \(4,5,6\) (grisés) ne sont pas utiles, ils sont inaccessibles depuis l'état initial.
L'état \(7\) est appelé un état puit : lorsqu'on l'atteint, il n'est plus possible d'atteindre un état accepteur.
Depuis l'état \(1\) le symbole \(b\) donne le choix entre plusieurs transitions
\((1 \xrightarrow{b} 1~ou~1 \xrightarrow{b} 2)\).
L'automate est donc non-déterminisme.
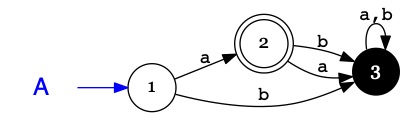
On ne pourrait pas faire plus simple.
Si !
On peut se contenter de décrire les chemins dans l'automate
qui sont utiles pour reconnaître les mots. Ce sont les chemins qui vont
d'un état initial à un état accepteur.
On peut donc éliminer les états inaccessibles, l'état puit et leurs transitions.
Une version équivalente de l'automate précédent
Définitions
Le langage d'une automate
\(A\), noté \(\mathcal{L}(A)\), est l'ensemble des mots reconnus/acceptés
par l'automate.
Un mot est accepté/reconnu par un automate
si
il existe un chemin dans l'automate
qui part d'un état initial
qui emprunte les transitions de l'automate correspondant aux symboles du mot
-a,b-> indique une transition sur le symbole \(a\) ou le symbole \(b\)
(3) désigne \(3\) comme état accepteur
En fin de semestre nous écrirons ensemble un traducteur AEF vers DOT.
Représentation d'un AEF par une table de transitions
Il existe une quatrième représentation, utile pour les algorithmes et l'implantation des automates,
qui consiste à décrire les transitions sous la forme d'un tableau.
statut des états
i
a
nom de l'automate
\(A\)
1i
2
3a
symbole
\(a\)
1
3
symbole
\(b\)
1,2
La ligne du haut indique le statut des états
La seconde ligne énumère les états de l'automate (on peut aussi y indiquer leurs statuts):
\(Q_i\) si l'état \(Q\) est initial,
\(Q^a\) s'il est accepteur et
\(Q_i^a\) s'il est à la fois initial et accepteur.
la colonne de gauche énumère les symboles de l'alphabet considéré
l'état cible de la transition \(Q \xrightarrow{s} \ldots\) se trouve en case \(A[Q][s]\),
au croisement de la colonne de l'état \(Q\) et de la ligne du symbole \(s\).
si un transition est non-déterministe,
la case de la transition contient tous
les états cibles séparés par une virgule
cf. 1,2 en case \(A[1][b]\)
l'état \(2\) n'a pas de transition pour le symbole \(b\),
la case \(A[2][b]\) est donc vide.
Avec cette représentation on voit en un coup d'oeil si l'automate est complet
et déterministe.
En revanche il est plus difficile d'avoir l'intuition du langage reconnu par l'automate.
Opérations sur les ensembles via leurs automates
Test du langage vide / Existence d'un chemin accepteur dans l'automate
Le langage d'un automate n'est pas vide si l'automate reconnaît au moins un mot :
Pour cela il suffit qu'il existe un chemin d'un état inital vers un état accepteur.
Considérons un automate \(A\),
dans quels cas peut-on affirmer que
\(\mathcal{L}(A)=\{\}\) ?
\(A\) n'a pas d'état accepteurs ?
\(A\) n'a pas de transition ?
\(A\) possède des états accepteurs mais inaccessibles depuis son/ses état/s initi(al/aux) ?
\(A\) possède un état-puit ?
Complémentaire d'un ensemble / Inversion du statut des états
Définition
Le complémentaire d'un langage \(L\) sur l'alphabet \(\Sigma\)
est l'ensemble des mots de \(\Sigma^*\) qui ne sont pas dans \(L\),
\(
\overline{L} \overset{def}{=} \Sigma^* - L
\)
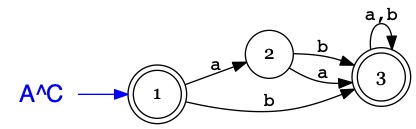
Si \(L = \mathcal{L}(A)\), ie. si le langage \(L\) est défini par un automate \(A\),
on peut constuire un automate \(A^C\) qui reconnait \(\overline{L}\).
On souhaite construire un automate \(A^C\),
qui rejette les mots que \(A\) reconnaît et accepte les mots que \(A\) rejette, ie.
Eurêka ! Si on inverse le statut des états de \(A\), les mots acceptés ne le seront plus,
les mots rejetés seront acceptés.
Mais attention il faut que l'automate \(A\) soit déterministe et complet avant de procéder à l'inversion,
sinon il vous manquera des cas d'acceptation.
Construction de \(A^C\)
déterminiser \(A\) si nécessaire
compléter l'automate avec un état puit si nécessaire
inverser le statut des états accepteurs / non-accepteurs
Illustration
L'automate \(A\) suivant est déterministe et complet.
Il reconnaît le langage \(\{a\}\).
L'automate \(A^C\) est le complémentaire de \(A\).
Il reconnaît le langage \(\overline{\{a\}}\) ie. \(\{a,b\}^*-\{a\}\)
Quizz complémentaire
On considère l'alphabet \(\Sigma=\{a,b\}\) et un AEF \(A\).
Parmi les propositions suivantes,
lesquelles représentent le complémenaire de \(\mathcal{L}(A)\) ?
\(\Sigma^*-\mathcal{L}(A)\)
\(\overline{\mathcal{L}(A^C)}\)
\(\mathcal{L}(A^C)\)
\(\overline{\mathcal{L}(A)}\)
\(\{a,b\}^*-\mathcal{L}(A^C)\)
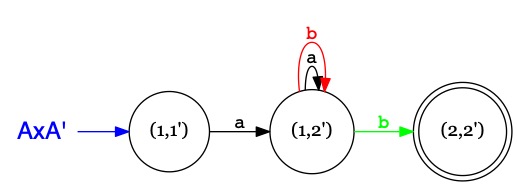
Intersection des langages L(A) et L(A') / Produit synchronisé des automates A et A'
On cherche à constuire un automate, noté \(A\times A'\),
qui simule l'exécution de \(A\) et \(A'\) lisant le même mot,
et qui accepte le mot si \(A\) et \(A'\) acceptent le mot.
Il faut donc simuler l'exécution simultanée et synchronisée de \(A\) et \(A'\).
Pour illustrer le principe, imaginez qu'on place un jeton 1 dans l'état initial de \(A\)
et un jeton 2 dans l'état initial de \(A'\).
Si \(A\) et \(A'\) peuvent faire une transition sur le même symbole
alors on déplace le jeton 1 dans \(A_1\) et le jeton 2 dans \(A_2\) vers les états cibles des transitions.
Pour simuler cette exécution, les états de \(A\times A'\) seront des couples d'états
faits d'un état de \(A\) et d'un état de \(A'\).
Les états accepteurs de \(A\times A'\) seront les états-couples où \(A\) accepte
et \(A'\) accepte.
On notera \(1',2',3',\ldots\) les états de \(A'\) pour bien les distinguer des états de \(A\).
L'état-couple \((1,4')\) indique que le jeton 1 est dans l'état \(1\) de \(A\)
et que le jeton 2 est dans l'état \(4'\) de \(A'\).
Si \(1 \xrightarrow{a} 2 \in A\) et \(4' \xrightarrow{a} 3' \in A'\)
alors on ajoute la transition \((1,4') \xrightarrow{a} (2,3')\) à l'automate \(A\times A'\).
Cela produit un nouvel état-couple \((2,3')\)
dont on doit construire les transitions possibles.
L'algorithme de construction des transitions de \(A\times A'\) se poursuite
en déplaçant les jetons dans \(A\) et \(A'\).
La construction s'arrête lorsqu'on ne produit plus de nouvel état-couple.
Il est inutile de commencer par énumérer tous les couples possibles d'états
car certains se réveleront inaccessibles.
En commençant la construction par les couples formés des états initiaux de \(A\) et \(A'\)
on ne construira que les couples accessibles.
En résumé
Les états de l'automate \(A\times A'\) sont des couples
formé d'un état de \(A\) et d'un état de \(A'\)
accessibles par le même mot.
Que se passe-t'il si l'un des automates, disons \(A\), est non-déterministe ?
Dans ce cas l'automate \(A\times A'\) sera non-déterministe.
Illustration
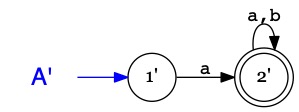
L'automate \(A\) reconnaît le langage \(\{~ w.b \mid w\in \Sigma^* ~\}\)
ie. l'ensemble des mots qui se terminent par \(b\).
L'automate \(A'\) reconnaît le langage \(\{~ a.w \mid w\in \Sigma^* ~\}\)
ie. l'ensemble des mots qui commencent par \(a\).
L'automate \(A\times A'\) reconnaît le langage \(\mathcal{L}(A)\cap\mathcal{L}(A')\)
ie. l'ensemble des mots qui se terminent par \(b\) et commencent par \(a\),
qu'on peut décrire par \(\{~ a.w.b \mid w\in \Sigma^*~\}\)
Le principe de construction reste le même dans le cas non-déterministe
Mais lorsque deux transitions sur le même symbole sont possibles dans \(A\),
il faut imaginer qu'on duplique le jeton de \(A\) pour explorer les 2 cas.
Puisque \(1 \xrightarrow{b} 1,~ 1 \xrightarrow{b} 2 \in A\) et \(2' \xrightarrow{b} 2' \in A'\)
alors
\(
\begin{array}{l}
(1,2') \xrightarrow{b} (1,2') \in A\times A'
\\
(1,2') \xrightarrow{b} (2,2') \in A\times A'
\end{array}
\)
Applications
Le produit d'automate a de nombreuses applications. En voici quelques unes :
en monitoring (resp. vérification) de programmes :
on combine un programme avec une propriété (resp. sa négation)
qu'on veut imposer (resp. vérifier).
Ainsi on limite (resp. s'assure que) les comportements du programme à ceux (resp. qui) respectent la propriété.
en sécurité pour faire la conjonction de deux politiques d'accés
et laisser passer les commandes autorisées par les 2 politiques.
en médecine pour savoir si deux protocoles médicalisés peuvent être appliqués
simulanément. Lorqu'on calcul le produit de \(A\times A'\) on obtient un automate dont les chemins sont
les déroulements compatibles des protocoles \(A\) et \(A'\).
Chacune de ces applications a fait l'objet d'un sujet d'examen disponible dans les annales A&G.
Quizz intersection
Quel est le nombre maximal d'états de \(A\times A'\) ?
\(|Etat(A)| \times |Etat(A')|\) ?
\(|Etat(A)| + |Etat(A')|\) ?
\(max(|Etat(A)|, |Etat(A')|)\) ?
\(min(|Etat(A)|, |Etat(A')|)\) ?
Si \(A\) possède la transition \(1 \xrightarrow{a} 2\)
et \(A'\) ne possède pas de transition \(4' \xrightarrow{a} 3\),
quelle sera la transition sur le symbole \(a\) issue de \((1,4')\) dans \(A\times A'\) ?
\((1,4') \xrightarrow{a} (2,P')\) où P' est un état-puit (donc non accepteur) de \(A'\)
\((1,4') \not\xrightarrow{a}\) : pas de transition sur le symbole \(a\)
\((1,4') \xrightarrow{a} (2,4')\) : \(A\) avance en 2 et \(A'\) reste en \(4'\).
La construction de l'automate \(A\times A'\) est impossible.
Sélectionnez les états-couples accepteurs de \(A\times A'\) qui sont accepteurs sachant que
\(1,3\in Acc(A)\) et \(2'\in Acc(A')\)
\(
(1,2') ?
(2,3') ?
(3,2') ?
(1,3') ?
\)
Soit \(A\) un automate opérant sur l'alphabet \(\Sigma\).
Quel est le langage reconnu par \(A\times A^C\) ?
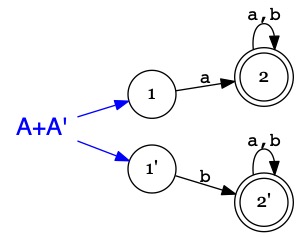
On cherche à construire un automate, noté \(A+A'\), qui accepte un \(mot\) si \(A\) l'accepte ou si \(A'\) l'accepte.
On doit tenter la reconnaissance du \(mot\) par \(A\) et si elle échoue, essayer avec \(A'\).
Il faut donc que l'automate \(A+A'\) examine les chemins correspondant au \(mot\) depuis les états initiaux de \(A\) et
depuis les états initiaux de \(A'\).
Il n'y a rien par particulier à faire : il suffit de dire que les automates \(A\) et \(A'\)
forment un seul automate \(A+A'\). Autrement dit, on range les deux automates dans le même tableau.
Exemple
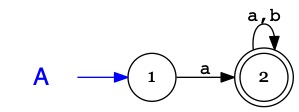
L'automate \(A\) reconnaît les mots sur \(\Sigma=\{a,b\}\) commençant par \(a\) :
\(A\)
1i
2a
\(a\)
2
2
\(b\)
2
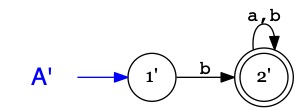
L'automate \(A'\) reconnaît les mots sur \(\Sigma=\{a,b\}\) commençant par \(b\) :
\(A'\)
1'i
2'a
\(a\)
2'
\(b\)
2'
2'
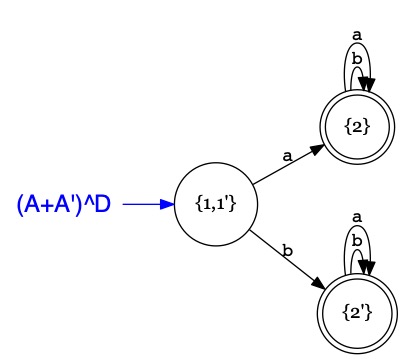
L'automate \(A+A'\) reconnaît les mots commençant par \(a\) ou par \(b\).
Sauf que l'automate \(A+A'\) a plusieurs états initiaux : ceux de \(A\) et ceux de \(A'\).
Il peut choisir dans quel état commencer ; il est donc non-déterministe.
Effectivement mais on peut le rendre déterministe.
C'est précisément le sujet de la prochaine leçon.
Nous verrons le procédé qui permet d'obtenir la version déterministe,
qui dans le cas présent est évidente.
Sachant cela, quels sont les automates qui reconnaissent le langage \(\overline{\mathcal{L}(A) \cup \mathcal{L}(A')}\) ?
\((A+A')^C\) ?
\(A^C + A'^C\) ?
\(A^C\times A'^C\) ?
\((A\times A')^C\) ?
Quels sont les automates qui reconnaissent le langage \(\overline{\mathcal{L}(A) \cap \mathcal{L}(A')}\) ?
\((A+A')^C\) ?
\(A^C + A'^C\) ?
\(A^C\times A'^C\) ?
\((A\times A')^C\) ?
Déterminisation d'un automate
Cette leçon est plus difficile que les autres.
Je vous conseille de la lire une fois ; puis de faire le test associé ;
puis de la relire une seconde fois. Vous la comprendrez mieux après avoir pratiqué.
Rappel
Un automate reconnaît un \(mot\) s'il existe un chemin dans l'automate capable d'accepter le \(mot\).
Lorsque l'automate est non-déterministe, il faut explorer tous les chemins possibles correspondant au \(mot\).
Illustration
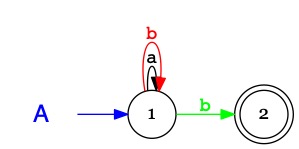
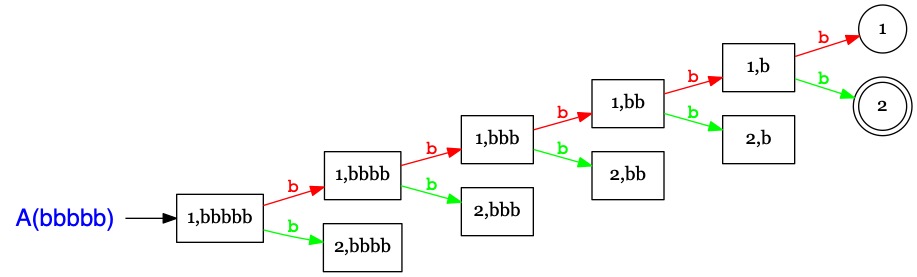
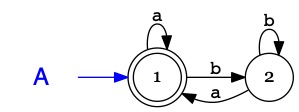
Considérons l'automate non-déterministe \(A\) qui reconnaît
les mots sur \(\Sigma=\{a,b\}\) se terminant par \(b\) :
\(A\)
1i
2a
\(a\)
1
\(b\)
1,2
Chaque fois que la reconnaissance rencontre une transition non-déterministe
il faut lancer une exécution supplémentaire par branche à explorer.
Cela nécessiterait plusieurs processeurs en parallèle ... pour exécuter un simple automate.
Il faut mener 6 exécutions en parallèles pour déterminer que \(bbbbb \in \mathcal{L}(A)\).
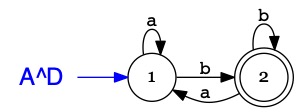
Tandis qu'avec la version déterministe \(A^D\)
il n'y a qu'un chemin à considérer pour décider si \(bbbbb\in\mathcal{L}(A^D)\)
et un seul processeur suffit.
On peut tirer partie du meilleur de chaque forme :
on décrit un automate sous sa forme non-détermini :ste \(A\), plus lisible ;
on utilise le procédé de déterminisation que nous allons voir pour construire \(A^D\) ;
on exécute sa version déterministe \(A^D\), plus efficace.
On peut faire le parallèle entre \(A \to A^D\) avec la compilation \(source \to assembleur\) :
un programme est écrit dans un langage source, fait pour les humains
(enfin la sous-catégorie des programmeurs) : il est lisible,
mais son exécution par un interpréteur ne serait pas efficace.
Certains aspects de la gestion mémoire, de l'ordonancement des instructions, ...
ne sont pas fixés et laissés au choix du compilateur.
la compilation effectue des choix en fonction des caractèristiques
du processeur cible et produit un exécutable en langage machine.
Le processeur exécute une version équivalente du programme,
en assembleur, plus efficace, mais moins lisible.
Construction de la version déterministe de A
On cherche à construire un automate \(A^D\), déterministe et équivalent à \(A\),
au sens où \(A\) et \(A^D\) reconnaissent les mêmes mots, ie. \(\mathcal{L}(A)=\mathcal{L}(A^D)\).
\(A^D\) doit simuler les multiples processeurs en train d'explorer les différents chemins d'exécution.
L'idée
Un état de \(A^D\) sera un ensemble d'états de \(A\), qu'on appelle configuration.
Chaque état de la configuration représentant un processeur en train de poursuivre
la reconnaissance du mot depuis cet état.
Exemple
Intéressons-nous à nouveau l'exécution de \(A(bbbbb)\),
mais cette fois, au lieu de noter des transitions entre états,
on considérera des transitions entre configurations
représentant les processeurs en activité.
Au départ, \(A(bbbbb) \to 1,bbbbb\) : on a un unique processeur actif dans l'état 1.
Cette situation se représente par la configuration \(\{1\}, bbbbb\).
La première transition \(\xrightarrow{b}\) est non-déterministe et conduit à deux exécutions parallèles :
depuis \(1, bbbb\) et \(2, bbbb\), ce que l'on résume par la configuration \(\{1,2\}, bbbb\)
où un processeur se charge de reconnaître \(bbbb\) depuis l'état 1 et un second processeur
effectue la reconnaissance depuis l'état 2.
Suite de l'exécution
Pour construire l'image de la configuration \(\{1,2\}\) par une transition
on applique la transition à un chacun des processeurs de la configuration.
par la transition \(\xrightarrow{a}\)
le processeur dans l'état 1 évolue de la manière suivante : \(1 \xrightarrow{a} \{1\}\)
le processeur dans l'état 2 ne peut faire de transition sur le symbole \(a\).
Son exécution s'arrête, ce qu'on peut représenter par la configuration \(\{\}\)
où il n'y a plus aucun processeur actif.
On résume ce cas par : \(2 \xrightarrow{a} \{\}\)
bilan : la configuration \(\{1,2\}\) évolue par \(\xrightarrow{a}\) en \(\{1\}\cup\{\}\) :
les processeurs activés ou arrêtés par la transition \(\xrightarrow{a}\).
Ce qui donne la transition \(\{1,2\} \xrightarrow{a} \{1\}\) dans \(A^C\).
par la transition \(\xrightarrow{b}\)
le processeur dans l'état 1 évolue de la manière suivante : \(1 \xrightarrow{b} \{1,2\}\)
car le non-déterminisme lance deux exécutions.
le processeur dans l'état 2 : \(2 \xrightarrow{b} \{\}\), son exécution s'arrête puisqu'il ne peut pas faire de transition sur \(b\).
bilan : la configuration \(\{1,2\}\) évolue par \(\xrightarrow{b}\) en \(\{1,2\}\cup\{\}\)
ce qui donne la transition \(\{1,2\} \xrightarrow{b} \{1,2\}\) dans \(A^C\).
Principe de déterminisation
On commence avec la configuration initiale \(C_i = Init(A)\) formée d'un processeur pour chacun des états initiaux de \(A\).
Soit \(C\) une configuration générée par l'algorithme,
on construit \(C'\), l'image de \(C\) par la transition \(\xrightarrow{a}\), de la manière suivante :
pour tout état \(Q\in C\), si \(Q \xrightarrow{a} Q'\in A\), on ajoute \(Q'\) à \(C'\).
on ajoute la transition \(C \xrightarrow{a} C'\) à \(A^D\).
L'algorithme ne produit que des configurations accessibles depuis la configuration initiale
puisque chaque nouvelle configuration \(C'\) est le résultat d'une transition à partir
d'une configuration \(C\) précédemment accessible. La première configuration accessible étant \(C_i\).
Exemple (suite)
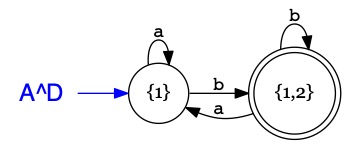
Le procédé de construction aboutit au tableau de transitions
\(A^D\)
{1}i
{1,2}
\(a\)
{1}
{1}
\(b\)
{1,2}
{1,2}
\(Etat(A^D) = \{~ \{1\},~\{1,2\}~\}\)
\(Init(A^D) = \{~ \{1\} ~\}\)
\(Acc(A^D) = \{~ \{1,2\} ~\}\)
Il nous reste à voir comment déterminer les états accepteurs de \(A^D\)
La reconnaissance de \(bbbbb\) par des configurations
\(
\{1\}, bbbbb \to \{1,2\}, bbbb \to \ldots \to \{1,2\}, b \to \{1,2\}
\)
résume l'arbre d'exécution qui se trouve du fait des ensembles d'états.
La séquence aboutit à la configuration \(\{1,2\}\) avec un processeur dans l'état 1 non-accepteur, qui rejette le mot
et un processeur dans l'état 2 qui accepte le mot.
Puisqu'il existe une exécution sur \(bbbbb\) qui atteint un état accepteur,
le mot est accepté par \(\{1,2\}\) qui doit donc être noté comme état accepteur de \(A^D\).
Finalement,
\(A^D\)
{1}i
{1,2}a
\(a\)
{1}
{1}
\(b\)
{1,2}
{1,2}
C'est le même automate \(A^D\) que précédement, sauf que cette fois
on a fait apparaître les configurations dans les états de l'automate.
Généralisation
\(Init(A^D) = \{ Init(A) \}\)
L'automate \(A^D\) a pour unique état initial l'ensemble des états initiaux de \(A\).
Les états accepteurs de \(A^D\) sont les configurations qui contiennent au moins un état accepteur de \(A\).
\(Etat(A^D) = \{ C \mid C \subseteq Etat(A) \}\)
Les états de \(A^D\) sont des configurations, qui sont des sous-ensembles de l'ensemble des états de \(A\).
Soit \(n\) le nombre d'états de \(A\) alors \(A^D\) peut avoir jusqu'à \(2^n\) états.
Lorsque ce nombre est atteint on parle d'explosion combinatoire.
Ce n'est pas fréquent mais pas impossible :
on sait construire des automates non-déterministes conçus spécialement
pour que la déterminisation provoque une explosion combinatoire.
Vous semble t'il possible qu'en DS je donne à déterminiser un tel automate à 8, 9 ou 10 états ?
Ouch... il faudrait au moins une feuille A3 pour le dessiner.
Quizz déterminisation
Soit \(A\) un automate à \(n\) états.
Que peut-on dire de l’automate \(A^D\) obtenu par l’algorithme de déterminisation ?
il a au plus \(2^n\) transitions ?
il a autant d’états accepteurs que \(A\) ?
il a au moins \(2^n\) états ?
il a un seul état initial ?
Par rapport à la version non-déterministe, la version déterministe d'un automate
a moins d'états ?
est plus lisible ?
s'exécute plus efficacement ?
nécessite plusieurs exécutions en parrallèle ?
Combinaison des opérateurs déjà vus
À l'aide des opérateurs déjà vus, il est possible d'en réaliser de nouveaux ; nous allons en voir 3.
Ensuite nous aurons suffisamment d'opérateurs à notre disposition pour passer aux applications des automates.
Restriction d'un langage
La notion de restriction vient des ensembles, elle n'est pas spécifique aux langages.
Étant donnés deux ensembles \(E\) et \(F\),
l'ensemble \(E\setminus F\) contient les éléments de \(E\) qui ne sont pas dans \(F\)
et on a l'égalité :
\(E\setminus F = E \cap \overline{F}\).
Ainsi, \(\mathcal{L}(A_1) \setminus \mathcal{L}(A_2)\),
l'ensemble des mots reconnus par \(A_1\)
« privé de »
des mots reconnus par \(A_2\), est égale à
\(\mathcal{L}(A_1) \cap \overline{\mathcal{L}(A_2)}\).
Pour s'en souvenir \(\mathcal{L}(A_1) \cap \overline{\mathcal{L}(A_2)}\)
se lit
"appartenant à \(\mathcal{L}(A_1)\) etpas à \(\mathcal{L}(A_2)\).
On a exprimé \(\mathcal{L}(A_1) \setminus \mathcal{L}(A_2)\) à l'aide des opérateurs
\(\cap\) et \(\overline{\mathcal{L}(.)}\)
qui ont des équivalents sur les automates.
On peut alors donner l'opération sur les automates correspondant
à l'opérateur \(\setminus\) sur les langages.
Puisque les langages sont des ensembles,
deux langages \(\mathcal{L}(A_1)\) et \(\mathcal{L}(A_2)\) sont égaux si
\(\mathcal{L}(A_1)\subseteq\mathcal{L}(A_2)\)
et
\(\mathcal{L}(A_2)\subseteq\mathcal{L}(A_1)\).
Automates équivalents
Deux automates \(A_1\) et \(A_2\) sont équivalents
s'ils reconnaissent le même langage
ie. \(\mathcal{L}(A_1)=\mathcal{L}(A_2)\)
Une première méthode pour tester l'équivalence de deux automates
consiste donc à montrer la double inclusion de leurs langages :
C'est le principe que je compte utiliser dans AutoGrade
pour la correction automatique des automates fournis par les élèves.
Quizz inclusion/intersection de langages
Indiquez les conditions qui doivent être vraise pour
garantir \(\mathcal{L}(A_1)\subset \mathcal{L}(A_2)\), ie. l'inclusion stricte
de \(\mathcal{L}(A_1)\) dans \(\mathcal{L}(A_2)\)
\(\mathcal{L}(A_2)\) contient au moins un mot qui n'est pas dans \(\mathcal{L}(A_1)\)
Les expressions régulières (regular expressions, en anglais, abbrégé en regexp)
sont une notation textuelle des automates.
Elle a l'avantage d'être très compacte, lisible et linéaire
mais ne convient qu'à la description d'automates très simples.
Les regexp sont utilisées dans de nombreux outils pour
sélectionner des éléments dans un ensemble de mots.
Citons entre autres
les outils unix grep et sed,
les fonctions avancées find/replace dans les éditeurs de texte,
les règles de firewall
et certains outils de générations de parseurs.
Voici des exemples de regexps et la notation AEF correspondante
Regexp
AEF
a.b
->1 -a-> 2 -b-> (3)
a*
->1 -a-> (1)
a*.b
->1 -a-> 1 -b-> (2)
a*.b*
->1 -a-> (1) -b-> 2 -b-> (2)
a|b
->1 -a-> (2) ; 1 -b-> (2)
(a|b)*
->1 -a,b-> (1)
a?
->(1) -a-> (2)
(a*.b*)*
->(1) -a,b-> (1)
((a|b)*.c*)*
->(1) -a,b,c-> (1)
Sur ces exemples on voit clairement l'avantage de la notation « regexp » pour les cas simples
et ses limites dans les derniers exemples dès que les expressions comportent
des * imbriquées.
La suite de la leçon est au format pdf
le temps que je la réécrive au format Moodle.
Plus la priorité d'un opérateur est élevée plus l'opérateur attire ses opérandes,
comme un aimant.
Ainsi, « l'opérateur de concaténation \({\Large.}\) est prioritaire sur
l'opérateur d'alternative \(\mid\) » signifie
que l'expression régulière \(a\mid b\mathop{\Large.}c\)
est implicitement parenthèsée \(a\mid(b\mathop{\Large.}c)\).
Si l'intention est d'écrire \((a\mid b)\mathop{\Large.} c\),
il faut mettre des parenthèses explicites.
Moi j'aurais tout simplement écrit a|b . b
Erreur ! les espaces sont élégants mais trompeurs.
Dans la majorité des langages de programmation ils ne jouent
aucun rôle [*] et sont éliminés dès la première phase de traitement
du fichier source, appelée analyse lexicale. Elle s'occupe de découper le fichiers
en suite de mots. Par exemple le code
"int main(){ return 0 }" est transformé en une séquence de lexèmes
[ "int" ; "main" ; "(" ; ")" "{" ; "return" ; "0" ; "}" ]
avant même le parsing.
Les espaces, les tabulations et les sauts de lignes ont déjà été éliminés
donc il ne faut pas compter dessus pour déterminer l'inteprétation d'une expression ambiguë.
Propriétés des opérateurs
L'opérateur de choix « \(\mid\) » est commutatif :
\(e_1 \mid e_2 = e_2 \mid e_1\)
L'opérateur de concaténation « \(\mathop{\Large.}\) » n'est pas commutatif :
\(e_1 \mathop{\Large.} e_2 \neq e_2 \mathop{\Large.} e_1\)
Dommage, j'aurais pu signé \(M.Hero\) au lieu d' \(Homer\).
Les opérateurs « \(\mid\) » et « \(\mathop{\Large.}\) » sont associatifs:
\((a \mid b) \mid c = a \mid (b \mid c)\)
et
\((a\mathop{\Large.}{b})\mathop{\Large.}{c} = a\mathop{\Large.}(b\mathop{\Large.}{c})\)
L'opérateur « \(\mathop{\Large.}\) » est distributif sur « \(\mid\) » :
\((a\mid b)\mathop{\Large.}{c} = a\mathop{\Large.}{c} \mid b\mathop{\Large.}{c}\)
et
\(a\mathop{\Large.}(b\mid c) = a\mathop{\Large.}{b} \mid a\mathop{\Large.}{c}\)
Une équivalence à connaître
Quelle que soient les expressions régulières \(e_1\) et \(e_2\),
\(~(e_1{\ast}\mathop{\Large.}e_2{\ast}){\ast}~\)
et
\(~(e_1\mid e_2){\ast}~\)
sont équivalentes,
au sens où elles définissent le même langage
\(\mathcal{L}(~(e_1{\ast}\mathop{\Large.} e_2{\ast}){\ast}~) = (\mathcal{L}(e_1)\cup\mathcal{L}(e_2))^* = \mathcal{L}(~(e_1\mid e_2){\ast}~)\)
Preuve (la partie intéressante seulement)
Tout mot de \((\mathcal{L}(e_1)\cup\mathcal{L}(e_2))^*\) est formé d'une alternance de mots de \(e_1\)
et de mots de \(e_2\). Considérons un mot avec une alternances de mots de \(e_1\) et de mots \(e_2\) ;
il peut s'écrire \(e_1^{i_1}.e_2^{j_1}.\ldots.e_1^{i_n}.e_2^{j_n}\) en choississant bien les valeurs
de \(n\) et des \(i_k,j_k\).
si le mot commence par \(e_2\) alors on prend \(i_1=0\) ;
si le mot se termine par \(e_1\) alors on prend \(j_n=0\).
Chacun des termes \(e_1^{i_k}.e_2^{j_k}\in \mathcal{L}(e_1{\ast}.e_2{\ast})\)
et donc la concaténation des \(n\) termes est dans
\(\mathcal{L}(e_1{\ast}.e_2{\ast})^* \overset{def}{=} \mathcal{L}(~(e_1{\ast}\mathop{\Large.} e_2{\ast}){\ast}~)\)
\(\Box\)
À propos de la traduction : regexp \(\to\) automate
Au delà de l'utilité de la notation regexp,
il y un intérêt pour un informaticien à faire l'exercice de traduction
regexp \(\to\) automate.
C'est l'occasion d'étudier un cas simple de compilateur.
Les similitudes avec un compilateur de programmes
La notation regexp est le langage source, textuel.
L'automate est le langage cible de la compilation : c'est la version exécutable.
La sémantique définit l'interprétation de chaque notation : celle du langage source
(les regexps) et celle du langage cible (les automates).
Dans le cas présent la sémantique
d'un automate \(A\) est l'ensemble \(\mathcal{L}(A)\) des mots reconnus par \(A\)
et on définit la même notion \(\mathcal{L}(e)\) d'ensemble de mots reconnus par
la regexp \(e\).
Le compilateur qui traduit \(e:regexp \to A:automate\) doit garantir
qu'il a préservé la sémantique, c'est à dire que l'automate généré
reconnaît le même langage que l'expression régulière de départ :
\(\mathcal{L}(A)=\mathcal{L}(e)\).
On retrouve les mêmes notions dans un compilateur C ou Java auquel on demande de produire
un code en assembleur ou en bytecode qui ait la même exécution observable
que le programme source écrit par l'utilisateur.
La traduction en automate introduit des \(\epsilon\)-transitions,
qui ne consomme pas de symbole
et servent uniquement à relier entre eux des morceaux d'automates.
On a exactement le même phénomème dans un compilateur de programme,
qui introduit des instructions NOP (No OPeration)
et des jumps inconditionnels.
La phase d'optimisation d'un compilateur consiste
à détecter que sous certaines conditions on peut simplifier l'automate généré,
à éliminer les \(\epsilon\)-transitions,
puis à minimiser l'automate.
En mode optimisé -o, un compilateur de programmes a exactement les mêmes objectifs.
[*]
Sauf en Python qui a repris la mauvaise idée de détecter les imbrications de boucles au moyen de l'indentation...
ce qui fût une source de bugs célèbres dans les programmes Fortan 68.
L'idée fût abandonnée en 1970 et fait malheureusement son retour.
Quizz expressions régulières
Cochez les propositions valides
{}* = {}
{}* = \$
Une regexp peut être non-déterministe.
On ne peut pas définir l'opération complémentaire sur les regexps.
Cochez les propositions valides.
L'expression régulière \((a\mid b){\ast})\) est équivalente à :
\((a{\ast} \mid b{\ast}) \mid \$\)
\((a{\ast}.b{\ast}){\ast}\)
\((b{\ast}.a{\ast}){\ast}\)
\((\$\mid b\mid a){\ast}\)
Cochez la regexp qui correspond à l'automate \(A\)
(a*.b.b*.a)*
(a*.b.a)*.b*
a*.b.b*.a
(b*.a)*.a*
Extension de la notation regexp
Donnez une définition sous forme de regexp des notations suivantes
optionnel :
e? = ...
au moins une fois :
e+ = ...
itérée 3 fois :
e^3 = ...
Élimination des \(\epsilon\)-transitions
Une \(\epsilon\)-transition \(Q \xrightarrow{\epsilon} Q'\) permet de passer de l'état source \(Q\)
à l'état cible \(Q'\) sans consommer de symbole du mot.
Ces transitions sont utiles pour la traduction/compilation de regexp
en automates, mais elles ont une contrepartie négative :
Rappelez vous que \(a.b= a.\epsilon.b = a.\epsilon.\epsilon.b = a.\epsilon^*.b\).
Autrement dit entre deux vrais symboles il y a autant d'\(\epsilon\) fictifs que l'on veut.
Ainsi, un automate qui contient une chemin d'\(\epsilon\)-transitions,
\(Q_1 \xrightarrow{\epsilon} Q_2 \xrightarrow{\epsilon} Q_3 \xrightarrow{\epsilon} Q_4\)
peut sauter de l'état \(Q_1\) à l'état \(Q_2\) ou \(Q_3\) ou \(Q_4\)
sans consommer de symbole du mot à lire.
On voit que la présence d'\(\epsilon\)-transitions introduit du non-déterminisme.
Élimination des \(\epsilon\)-transitions
Le but est de produire un automate équivalent
(ie. qui reconnaît le même langage) et qui ne contient que des transitions sur
des symboles de l'alphabet.
Notez que \(\epsilon\) n'est pas un symbole de l'alphabet :
il n'y a pas besoin d'introduire un symbole spécial dans \(\Sigma\) pour écrire un mot de longueur 0.
Principe d'élimination des \(\epsilon\)-transitions
L'élimination consiste à remplacer un chemin
\(Q~ (\xrightarrow{\epsilon})^* \xrightarrow{a} (\xrightarrow{\epsilon})^* ~Q'\)
par une transition directe
\(Q \xrightarrow{a} Q'\)
Exemple
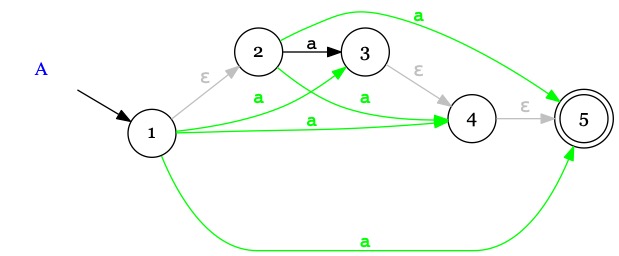
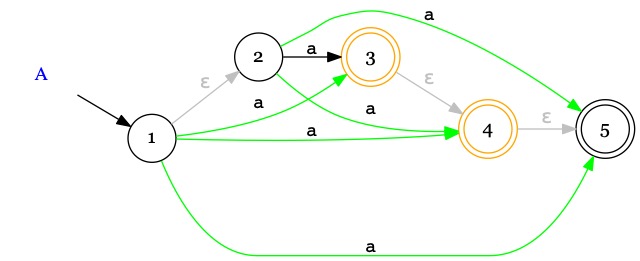
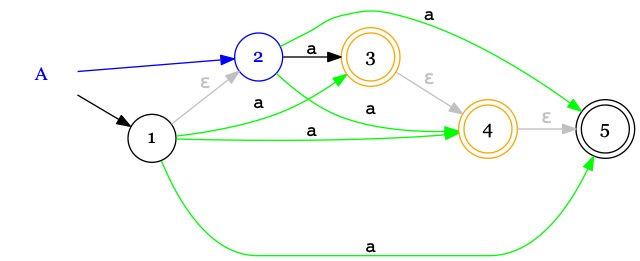
Considérons un extrait d'automates comportant un vrai symbole \(a\) et des \(\epsilon\)-transitions.
On commence par construire
un raccourci ie. une transition \(\xrightarrow{a}\)
pour chaque chemin contenant des \(\epsilon\) et un vrai symbole.
Attention à ne pas en oublier.
On rend accepteur la source d'une \(\epsilon\)-transition qui pointe vers un état accepteur.
Explication :
Imaginons que 1 soit l'état initial. Arrivé à l'état 3 ou 4 après avoir lu un \(a\) on n'accepte pas le mot \(a\)
puisque \(3,4\notin Acc\) ; en revanche, sans symbole supplémentaire, il est possible de sauter dans l'état 5
par le chemin \(3 \xrightarrow{\epsilon} 4 \xrightarrow{\epsilon} 5\) et d'accepter le mot \(a\) puisque \(5\in Acc\).
Au final, le mot \(a\) est accepté par l'automate
puisqu'il existe une exécution qui l'accepte
(cf. la définition de la reconnaissance d'un mot par une AEF).
Pour éviter d'avoir à explorer des exécutions faîtes d'\(\epsilon\)-transitions
jusqu'à l'état \(5\in Acc\), on rend les états 3 et 4 accepteurs.
On supprime les \(\epsilon\)-transitions devenues inutiles puisque les raccourcis
simulent leur effet.
Quizz élimination des \(\epsilon\)-transitions
Cochez les propositions valides :
Les \(\epsilon\)-transitions propagent les états accepteurs en arrière.
Les \(\epsilon\)-transitions propagent les états accepteurs en avant.
L'élimination des \(\epsilon\)-transitions peut produire un automate
avec des parties déconnectées.
L'élimination des \(\epsilon\)-transitions ne risque pas de produire un automate
avec des parties déconnectées.
On note \(A^{\overline{\epsilon}}\) l'automate obtenu par élimination
des \(\epsilon\)-transitions de \(A\).
Cochez les propositions valides :
Cette leçon présente une autre traduction : automate \(\to\) équations de langages.
L'intérêt est que les équations de langages établissent le lien entre les automates
et les grammaires, que nous étudierons au chapitre suivant.
On peut représenter un automate par un système d'équations de langages.
Auparavant il nous faut définir la notion de langage associé à un état d'automate.
Langage associé à un état d'automate
Étant donné un état \(Q\) d'un automate \(A\),
le langage \(L_Q\) associé à l'état \(Q\) est le langage
que reconnaîtrait l'automate \(A\) si son état initial était \(Q\).
Mathématiquement,
Mais alors, si l'état 1 est l'état initial de \(A\),
le langage de \(A\) c'est \(L_1\) ?
Effectivement. La notion de langage associé à un état est générale
et le langage de l'automate est un cas particulier.
Toutefois pour donner une réponse complète, il faut envisager le cas où \(A\) a plusieurs états initiaux.
Le langage reconnu par un automate est l'union de langages de ses états initiaux.
On peut relier les langages des états de \(A\) par des équations de la forme :
\(L_i\) = une expression régulière comportant des variables \(L_i\)
La transition \(2 \xrightarrow{a} 3\) établit un lien entre le langage
\(L_2\) et le langage \(L_3\) :
le langage \(L_2\) est constitué des mots \(L_3\) précédé du symbole \(a\)
puisque pour reconnaître un mot depuis l'état 2, il faut commencer par lire un \(a\)
puis lire un mot reconnu par \(L_3\).
C'est ce que traduit l'équation
\(
L_2 = a \mathop{\Large.}{L_3}
\)
L'état 4 étant accepteur, si on démarre dans l'état 4 on peut reconnaître
\(\epsilon\) représenté par l'expression régulière « \(\$\) ».
La transition \(4 \xrightarrow{a} 4\) dit qu'on peut former un mot de \(L_4\)
en ajoutant un \(a\) devant un mot de \(L_4\).
Ce qui se traduit par l'équation :
\(
L_4 = \$ \mid a \mathop{\Large.} L_4
\)
Mais ça n'a pas de sens : pour faire un mot de \(L_4\) il faut un mot de \(L_4\).
C'est presque juste ! Si on avait comme équation \(L_4 = a \mathop{\Large.} L_4\)
on ne pourrait effectivement pas former de mots et on aurait \(L_4 = \{\}\)
puisque \(\{\}\) est solution de l'équation :
\(\{\} = a \mathop{\Large.} \{\}\).
J'ai pigé ! L'équation dit que \(\epsilon\in L_4\), on a donc au moins un mot,
à partir duquel on peut construire \(a.\epsilon\), on a alors un nouveau mot \(a\)
à partir duquel on peut construire \(a.a\), on a alors un nouveau mot \(a.a\), et ainsi de suite.
C'est parfaitement juste. Et quel est alors le langage de \(L_4\) ?
\(L_4 = \{~\epsilon,~a,~a.a,~a.a.a,~\ldots~\}\)
Peut-on éliminer l'ambiguité de ces \(\ldots\) ?
\(L_4 = \{~a^n \mid n\in\mathbb{N~\}}\)
Peut-on l'écrire sous forme de regexp ?
\(L_4 = a{\ast}\)
À partir de ces remarques
on peut formuler un principe général.
Construction des équations reliant les langages des états d'un automate \(A\)
Si \(Q\in Acc(A)\)
\(
L_Q = \$ \mid s \mathop{\Large.} L_{Q'} \mid \ldots \textit{ pour chaque } Q \xrightarrow{s} Q'\in A
\)
Si \(Q\notin Acc(A)\)
\(
L_Q = s \mathop{\Large.} L_{Q'} \mid \ldots \textit{ pour chaque } Q \xrightarrow{s} Q'\in A
\)
Si \(Q\notin Acc(A)\) et \(Q\) n'a pas transition sortante
\(
L_Q = \{\}
\)
Vous avez mis des \(\ldots\)
Oui, car la formulation exacte n'est pas très lisible :
\(L_Q = \{\} \mathop{\mid}\limits_{Q \xrightarrow{s}Q'\in A} s \mathop{\Large.} L_{Q'} \mathop{\mid}\limits_{Q\in Acc(A)} \$\).
Exemple (fin)
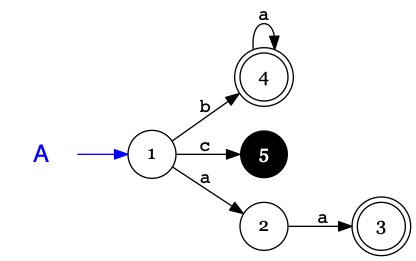
Pour l'automate \(A\) on obtient le système d'équations de langages :
automate
système d'équations
solutions
\(
\left\{\begin{array}{rcl}
L_1 &=& a \mathop{\Large.} L_2 \mid b \mathop{\Large.} L_4 \mid c \mathop{\Large.} L_5
\\ L_2 &=& a \mathop{\Large.} L_3
\\ L_3 &=& \$
\\ L_4 &=& a \mathop{\Large.} L_4 \mid \$
\\ L_5 &=& \texttt{\{\}}
\end{array}\right.
\)
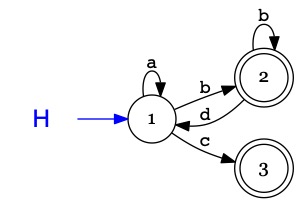
Cochez les équations de langages qui correspondent à l'automate \(H\),
attention aux pièges.
\(L_3 = c \mathop{\Large.} L_1 \mid \$\)
\(L_1 = a \mathop{\Large.} L_1 \mid b\mathop{\Large.} L_2 \mid \$\)
\(L_2 = L_1 \mathop{\Large.} b \mid L_2 \mathop{\Large.} d \mid \$\)
\(L_2 = b \mathop{\Large.} L_2 \mid d \mathop{\Large.} L_1\)
Résolution d'un système d'équations de langages (Lemme d'Arden)
Cette leçon présente la traduction équations de langages \(\to\) regexp.
La boucle sera ainsi bouclée :
regexp \(\to\) automate \(\to\) équations de langages \(\to\) regexp
Ce qui démontre l'équivalence des trois représentations puisqu'on peut passer
de l'une à l'autre.
regexp \(\to\) automate
automate \(\to\) équations de langages
automate \(\to\) regexp (via les équations de langages)
Résolution d'un système d'équations de langages
La résolution du système d'équations
permet d'obtenir l'expression régulière qui décrit le langage associé à chaque état de l'automate.
Le principe de résolution>
est essentiellement la méthode classique étudiée
en lycée avec un complément spécifique au cas des langages
- connu sous le nom de Lemme d'Arden - qui permet de résoudre
le cas des équations récursives, ie. de la forme \(L = \ldots L \ldots\).
Lemme d'Arden
La plus petite solution d'une équation récursive de la forme
\(
L = e_1 \mathop{\Large.} L \mid e_2
\)
est
\(~~L = (e_1){\ast} \mathop{\Large.} e_2~~\)
si \(\epsilon\notin\mathcal{L}(e_A)~~\),
et \(~~\Sigma^*\) sinon.
La démonstration du Lemme d'Arden, optionnelle cette année, est disponible au format
pdf.
L'algorithme de traduction : automate \(\to\) regexp consiste à générer les équations de langages
et les résoudre au moyen de l'élimination de Gauss et du lemme d'Arden.
Toutefois quand l'automate est suffisamment simple. On peut utiliser la méthode d'Homer.
Je le laisse la présenter :
On écrit sous forme d'expression régulière chaque chemin d'un état initial à un état accepteur.
S'il y a le choix entre plusieurs chemins,
on les décrit tous, séparés par l'opérateur de choix « \(\mid\) », un peu à la manière de votre notation
AEF. Et il faut ajouter une \(\ast\) quand le chemin reboucle sur lui-même.
Exemple
Considérons l'exemple
L'automate comporte plusieurs chemins
\(\to 1\xrightarrow{c} 3\),
qui correspond à la regexp « \(c\) »,
\(\to 1 \xrightarrow{a} 1 \xrightarrow{b} 2 \xrightarrow{b} 2\),
qui correspond à la regexp « \({a\ast}\mathop{\Large.}{b}\mathop{\Large.}{b\ast}\) »
avec des \(\ast\) sur les boucles.
Depuis l'état 2 on a donc le choix entre \((\$\mid d)\).
Le \(\$\) correspond à l'arrêt possible en 2 puisque l'état est accepteur ;
le \(d\) correspond à la transition \(2\xrightarrow{d}1\) qui fait reboucler sur l'état initial
et indique qu'il faut ajouter une étoile.
On obtient au final l'expression régulière (séduisante mais erronée)
\(
c \mid (~ {a\ast}\mathop{\Large.}{b}\mathop{\Large.}{b\ast}\mathop{\Large.}(\$\mid d) ~){\ast}
\)
Attention Homer, méfie toi de tes intuitions,
c'est presque pas ça du tout [!]
C'est l'occasion de citer l'aphorisme de H.L.Mencken (1880-1956) :
« Pour chaque problème il y a une solution qui est simple, claire, élégante ... et fausse. »
correction:
Après avoir tourné dans la boucle
\((~ {a\ast}\mathop{\Large.}{b}\mathop{\Large.}{b\ast}\mathop{\Large.}(\$\mid d) ~){\ast}\)
on retourne dans l'état 1 et on a la possibilité de prendre le chemin \(c\) ... ou pas.
L'expression correcte est donc :
Ce n'est pas la seule solution, il y a de nombreuses expressions régulières équivalentes.
La technique de résolution d'Arden en fournit une autre :
\(
(a \mid b\mathop{\Large.}{b\ast}\mathop{\Large.}{d}){\ast} \mathop{\Large.}~ (b\mathop{\Large.}{b\ast}\mid c)
\)
Pour les curieu.(x | ses)
La version correcte de l'intution d'Homer s'appelle la méthode des têtes de boucles de Bourdon.
[!]
« C'est presque pas ça » est une expression familiale
dont la signification, pas tout à fait limpide, est
qu'il y a de l'idée mais que c'est quand même bien faux.
Minimisation
TODO
Applications, Limitations, Extensions
Applications
Jusqu'à présent le cours sur les automates s'est focalisé sur les définitions et les opérateurs.
Les exercices vous ont permis de vous familiariser avec la technique.
Dans le cours et les exercices nous avons considéré l'alphabet \(\Sigma=\{~a,b~\}\) pour rester simple.
C'était pour apprendre le \(b.a.ba\) des automates mais il est temps de passer à de vraies applications.
Je vous propose d'illustrer les usages possibles des automates à travers deux sujets de reflexion :
La vérification de propriétés de drivers chez Microsoft
[ pdf ]
Ces deux sujets ne se prêtent pas bien à un format interactif Moodle.
Aussi je vous propose de préparer les sujets (un par groupe) et de consacrer
une séance d'une heure d'exposé à le présenter à l'autre groupe.
Il y a dans chaque sujet suffisamment de questions pour que chaque élève
de chaque groupe participe à l'exposé.
Il faudra prendre le temps et apporter un soin particulier à la présentation du sujet.
Limitations
Les automates n'ont pas de mémoire, y compris de la trace d'exécution en cours.
À chaque instant de l'exécution les seules informations dont dispose l'automate pour
choisir son prochain pas sont : l'état dans lequel il se trouve et le prochain symbole.
Sans mémoire il est impossible de reconnaître certains langages.
En particulier tous les langages pour lesquels il est nécessaire de compter
pour reconnaître un mot.
Exemples de langages non-reconnaissables par les AEFs
Les mots sur \(\{~a,b~\}\) qui ont autant de \(a\) que de \(b\)
\(\{ w\in\{a,b\}^* \mid |w|_a = |w|_b\}\) n'est pas reconnaissable par un AEF.
\(\{~ a^n.b^n \mid n\in\mathbb{N~\} }\) n'est pas reconnaissable par un AEF.
Là encore il faudrait compter le nombre de \(a\) lus pour ensuite accepter le même nombre de \(b\).
Les premiers concepteurs de compilateurs espéraient utiliser les automates
pour reconnaître le programme bien formés et pouvant être traduits.
Cet exemple fut une révélation ... de la limitation des automates :
imaginez qu'on remplace le symbole \(a\) par « ( » et \(b\) par « ) », que dit ce exemple ?
Qu'on ne peut pas reconnaître les mots de la forme \((^n . )^n\),
ie. les expressions avec autant de parenthèses ouvrantes que de parenthèses fermantes.
Il n'y avait donc aucun espoir d'analyser avec ces automates les langages de programmation
qui font un usage immodéré d'expressions bien formées faites de [,],{,},(,).
Remarque théorique
Si on borne la taille du plus long mot alors tout devient possible.
Dans les machines actuelles le plus grand entier est \(2^{63}-1\).
C'est une borne qui limite le nombre de cellules mémoire de l'ordinateur
donc elle limite la taille du plus long mot (en considérant que l'ensemble de la mémoire de l'ordinateur est un immense mot fait de 0 et de 1).
Donc je peux tout programmer en automates !
Certes, c'est vrai, d'un point de vue théorique,
mais les automates atteignent des tailles monstrueuses...
Exerices
Donnez un automate sur \(\Sigma=\{~a~\}\)
qui reconnaît le langage \(\{ a^n \mid n~\textit{impair}, n \leq 5\}\)
Donnez un automate sur \(\Sigma=\{~a,b~\}\) qui reconnaît le langage
\(\{ w \in\{a,b\}^* \mid |w|\leq 3,~ |w|_a \leq |w|_b\}\)
ie. les mots de moins de 3 lettres qui ont moins de \(a\) que de \(b\).
Indication : Pour construire l'automate, considérez que les états
sont des couples \((n_a,n_b)\) qui comptent le nombre de \(a\) et de \(b\) déjà vus.
L'automate commence dans l'état \((0,0)\) ; une transition sur \(a\)
fait passer dans l'état \((1,0)\) ; une transition sur \(b\) augmente le compteur de \(b\).
À vous d'énumérer les transitions et de déterminer quels sont les états accepteurs.
Combien d'états à cet automate ?
Extension: automates à une pile
Les automates à une pile (AUP) sont une extension directe des AEFs
qui permet de reconnaître les langages précédents sans avoir besoin de borner la taille des mots.
Les conditions d'acceptation d'un mot sont celles d'un AEF
auxquelles on ajoute une condition sur l'état de la pile au début et à la fin de l'exécution.
Condition d'acceptation d'un mot par un AUP
Un mot est reconnu par un AUP s'il existe une exécution
qui commence dans un état initial avec une pile vide ;
qui consomment toutes les lettres du mot ;
qui se terminent dans un état accepteur avec une pile vide
Transitions d'un AUP
Les transitions sont de la forme \(Q \underset{[P]}{\xrightarrow{s}} Q'\)
et Q -s[P]-> Q' en mode ascii
où \(P\) est une séquence d'instructions de manipulation de la pile
« s? » teste si le sommet de la pile contient le symbole \(s\)
et retourne le résultat du test
« _? » teste si la pile est vide et retourne le résultat du test
« !s » place le symbole \(s\) sur le sommet de la pile et retourne \(true\)
« % » dépile le symbole en sommet de pile et retourne \(true\)
La transition \(Q \underset{[P]}{\xrightarrow{s}} Q'\) est exécutable si
le symbole lu correspond à \(s\), et
si toutes les instructions de la séquence \(P\) retournent \(true\).
accepte de lire un \(b\) uniquement si un \(a\) est présent sur la pile
a? puis . dépile le sommet.
accepte dans l'état (2) si la pile est vide ; ce qui garantie qu'on a lu autant de \(a\) que de \(b\).
Il reconnaît le langage \(\{~ a^n.b^n \mid n\in \mathbb{N~\}}\)
Les AUPs peuvent donc traiter les expressions bien parenthèsées.
Ces automates sont utilisées par les générateurs de parseurs Yacc et Bison
pour produire des parseurs très efficaces.
Mais ils ont aussi leurs limitations.
Ils sont capables de reconnaître le langage
\(\{~ a^n.b^n \mid n\in\mathbb{N~\}}\)
mais pas
\(\{~ a^n.b^n.c^n \mid n\in\mathbb{N~\}}\).
On sait effectuer plusieurs opérations (intersection, union) sur les AUPs
mais on ne sait pas les déterminiser.
En option
Les \(curieu\cdot (x \mid ses)\) qui souhaitent approfondir la question peuvent lire la leçon optionnelle
[pdf].