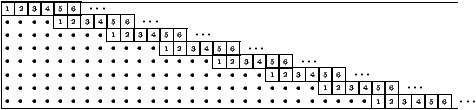
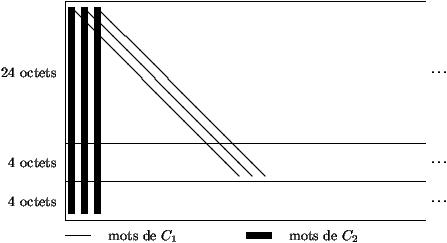
Décodage. Le décodage du tableau de la Figure 2 se fait dans un premier temps colonne par colonne en utilisant un décodeur de C2 corrigeant une erreur. Si la colonne n'est pas un mot de C2 et que la correction échoue, les 28 symboles retournés par le décodeur sont marqués comme effacés. À partir de la 109-ième colonne décodée on commence à décoder des diagonales (à retard 4) avec un décodeur de C1 corrigeant 4 effacements ou moins. Cela implique en particulier que le décodeur de C1 recevra en plus du mot à décoder la liste des positions des effacements.