 |
|
Ce dernier chapitre est consacré au traitement automatique de données :
Le projet donnera une illustration concrète de cette activité très fréquente
chez un informaticien.
Automates, expressions régulières, équations de langages et maintenant les grammaires ...
Mais pourquoi y'a-t'il tant de représentations différentes si elles sont équivalentes ?

Premier élément de réponse :
Deuxième élément de réponse :
Il existe plusieurs types de grammaires.
Troisième élément de réponse :
Les grammaires dites à attributs permettent de faire des traitements informatiques (calculs et/ou traduction)
pendant la reconnaissance.
Les grammaires à attributs forment une catégorie de langages de programmation spécialisés
dans le traitement de données : il en existe plusieurs variantes selon l'outil
de génération du parseur utilisé (Yacc, Bison, Javacc, AntLR).
C'est un concept qu'il faut maîtriser. Vous aurez l'occasion de vous y exercer avec le projet.
La même idée a été découverte 4 fois dans des contextes différents :
Peu importe la notation c'est la même idée.
Retenez qu'une grammaire peut-être utilisée dans les deux sens :
pour générer des phrases
(en composition automatique de littérature ou de musique [*])
ou pour reconnaître/analyser des données en vue d'un traitement
informatique. Nous nous intéresserons uniquement au second cas dans ce cours.
À l’origine la notion de grammaire a été inventée par des linguistes pour définir les phrases syntaxiquement correctes des langues naturelles. On peut par exemple définir la grammaire du français qui indiquent les phrases syntaxiquement correctes du français ;
Exemple
Mais cette phrase n'a pas de sens.
On ne s’occupe pas ici du sens de la phrase mais uniquement de sa structure grammaticale.
De la même manière on peut décrire les programmes syntaxiquement corrects d’un langage de programmation. On ne s’occupe pas ici du sens, ni de la terminaison, ni du bon fonctionnement du programme, mais juste de sa structure.
Exemple
On pourrait améliorer la grammaire pour indiquer/détecter qu'il ne faut jamais écrire 1/0.
On pourrait mais on compliquerait la grammaire et on ne réussirait pas à capter
tous les cas de division par 0. Par exemple z=0; x=1/z;
serait sans doute accepté. La détection de ce type d'erreurs
n'est pas le rôle de la grammaire c'est celui d'autres étapes de la compilation
(vérification de types, analyse statique de runtime errors).
Une grammaire \(G = (\Sigma, \mathcal{N}, germe, \mathcal{R})\) est définie par
Exemples
génère/reconnaît les mots du langage \(\mathcal{L}(a\ast)\), qui est régulier ie. reconnaissable par un AEF.
génère/reconnaît les mots du langage \(\{~a^nb^n \mid n\in\mathbb{N~\}}\), qui est algébrique ie. reconnaissable par une AUP.
génère/reconnaît les mots du langage \(\{~ \omega \mid |\omega|_a=|\omega|_b~\}\), qui est algébrique ie. reconnaissable par une AUP.
génère/reconnaît le même langage que \(G_3\). Elle est plus difficile à comprendre que \(G_3\) mais a l'avantage d'être déterministe et de garantir la terminaison de l'analyse syntaxique.
Production versus Mot
On appelle production un séquence de symboles de \(\Sigma\cup\mathcal{N}\) ie. formée de terminaux et de non-terminaux, par exemple \(a\mathop{\Large.} S\mathop{\Large.} b\).
Un mot au sens habituel est en donc une production de \(\Sigma^*\).
Réécriture
La règle \(\omega\xrightarrow{r}\omega'\in\mathcal{R}\) d’une grammaire permet de réécrire la production \(\psi\) en \(\psi'\), si les productions \(\psi\) et \(\psi'\) peuvent se décomposer en trois parties : un début \(d\) et une fin \(f\) communes telles que
- \(\psi = d.\omega.f\)
- \(\psi' = d.\omega'.f\)
On écrit alors \(\psi \vdash_{r} \psi'\)
Dérivation
La grammaire \(G\) permet de dériver la production \(\psi'\) à partir de \(\psi\) s'il existe une séquence de règles \(r_1,...,r_k\) de \(\mathcal{R}\) qui transforme \(\psi\) en \(\psi'\) par réécritures successives
\( \psi \vdash_{r_1} \ldots \vdash_{r_k} \psi' \)On écrit alors \(\psi \vdash_{\mathcal{R}}^* \psi'\).
Exemple
Langage associé à une grammaire
La production d'une grammaire \(G=(\Sigma,\mathcal{N},germe,\mathcal{R})\) est l'ensemble des productions que l'on peut obtenir par dérivation \(\vdash^*_{\mathcal{R}}\) à partir du germe de la grammaire.
\( \mathcal{P}(G) = \{ \psi\in(\Sigma\cup\mathcal{N})^* \mid germe \vdash_{\mathcal{R}}^* \psi \} \)Le langage d'une grammaire est l'ensemble des productions qui sont des mots, ie. qui appartiennent à \(\Sigma^*\).
\( \begin{array}{rcl} \mathcal{L}(G) &=& \mathcal{P}(G)\cap \Sigma^* \\ &=& \{ m\in\Sigma^* \mid germe \vdash_{\mathcal{R}}^* m \} \end{array} \)
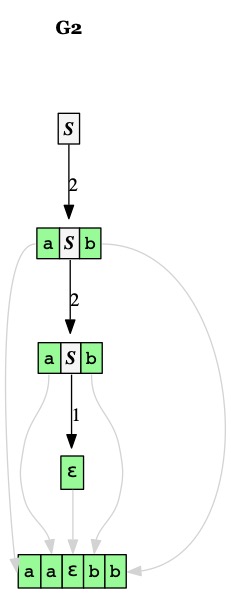
Un arbre de dérivation
Un arbre de dérivation est une représentation structurée de la séquence des dérivations depuis le germe de la grammaire. L'arbre indique par sa structure sur quel non-terminal est appliquée chaque règle.
La production d'un arbre de dérivation est la séquence de ses feuilles. Si cette production appartient à \(\Sigma^*\), on parle du mot de l'arbre
Voici deux représentations d'un même arbre de dérivation du mot \(aabb\) par la grammaire \(G_2\)
|
|
|
|
| ||||||||||||||||||||||
| ||||||||||||||||||||||||||
Exemples d'arbre de dérivation
Nous avons présenté la notion de grammaire sous l'angle des dérivations possibles.
L'usage de grammaires génératives est limité à la production
automatique de littérature, musique et de séquences de tests.
L'usage le plus courant des grammaires est la reconnaissance de format de données appelée analyse syntaxique (parsing en anglais).
Toutes les grammaires ne permettent pas de générer un analyseur syntaxique (parseur en anglais).
Pour qu'une grammaire permette une analyse syntaxique il faut qu'elle respecte deux critères
Nous allons étudier les techniques d'élimination de la récursivité gauche
et des ambiguités à travers les exercices.
L'objectif du projet est de produire la représentation graphique d'un automate
au format .dot pour l'outil graphviz
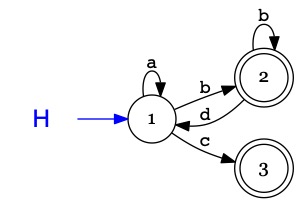
AEF(H){ ->1 -a-> 1 -b-> (2) -b-> (2) -d-> 1 -c-> (3) ; }
Vous serez guidés
Projet collaboratif
Comment collaborer ?
Il faut rendre au plus tard le VENDREDI 22 JANVIER un fichier .zip contenant votre répertoire Projet/
Plusieurs niveaux d'investissements et la note associée
À l'issue des TP sur les parseurs, le projet devrait vous prendre 4 × (1h30, le temps que j'ai mis pour viser 14/20) = 6h.
Les fichiers nécessaires au projet sont sur le dépôt [git]
Il contient
Pour vous aider à concevoir votre grammaire,
je fournis également, pour chaque exemple, au format
[pdf],
les arbres (simplifiés) de reconnaissance/dérivation
produit par mon parseur lors de la traduction.
Ça ne vous est pas demandé dans le projet !
Dans ce cours nous allons voir comment concevoir la grammaire qui reconnaît la notation
AEF utilisé dans ce cours.
Comment naît une notation ?
En rédigeant ce cours j'ai constaté qu'il n'y avait pas de notation
lisible, simple et compacte pour les AEF.
J'ai donc inventé ma propre notation par déformation professionnelle.
Les étapes de conception d'un traducteur
Lorsqu'une notation (AEF) n'est pas acceptée par les outils existants (graphviz dans notre cas) il faut concevoir un traducteur de la nouvelle notation vers le format d'entrée des outils : \(AEF \to DOT\) en ce qui nous concerne.
Analyse d'un exemple caractéristique
Pour concevoir une grammaire on commence par écrire un ou des exemples qui illustre les possibilités cas de la nouvelle notation. J'ai rassemblé les différents cas dans un seul exemple :
AEF(A){ ->1 -a->2 -b->1 ; ->2 -a->(3) ; 3-a,b->3 ; }
On analyse l'exemple pour y trouver des régularités.
| AEF( | A | ){ | -> 1 | -a-> | 2 | -b-> | 1 | ; | -> 2 | -a-> | (3) | ; | 3 | -a,b-> | 3 | ; | } |
| AEF( | Ident | ){ | Start | Arrow | Target | Arrow | Target | ; | Start | Arrow | Target | ; | Start | Arrow | Target | ; | } |
| AEF( | Ident | ){ | Start | Step | Step | ; | Start | Step | ; | Start | Step | ; | } | ||||
| AEF( | Ident | ){ | Path | Path | Path | } | |||||||||||
Proposition de grammaire
Puisque les états sont des identificateurs, pourquoi créer un non-terminal \(State\) alors qu'on aurait pu simplement écrire \(Ident\) ?
Il est vrai que les états sont actuellement des identificateurs, mais ça pourrait évoluer.
On pourrait étendre la notion d'états afin de reconnaître d'autre notations utilisées dans le cours telles que \(1'\), \((1,2)\), \(\{1,3\}\).
Le fait d'utiliser un non-terminal \(State\) prépare l'évolution de la grammaire.
Si on a besoin d'étendre la reconnaissance des états il suffira de changer la ligne qui définit \(State\)
sans avoir à toucher au reste de la grammaire.
En exercice nous ajouterons la possibilité d'écrire des états « primés » ie. suivis de \('\).
Les outils d'analyse lexicale (Lexer) autorisent les expressions régulières \((.)?\), \((.)+\), \((.)\ast\). Certains outils d'analyse syntaxique (Parser) l'autorisent dans la grammaire. et nous en avons fait usage. Elles sont pratiques mais pas indispensables. D'autres outils ne l'autorisent pas et au final tous les outils éliminent les expressions régulières en donnant une traduction sous forme de règles de grammaires. Mais surtout, l'élimination des expressions régulières est nécessaire avant de compléter le parser avec des calculs.
La forme \((e \cdot NT1) \mid (e\cdot NT2)\) qui est équivalente
contient un non-déterminisme qui ne convient pas au parseur
puisqu'il doit choisir entre les deux alternatives au moment de reconnaître \(e\).
L'ajout d'une règle repousse le moment du choix après la reconnaissance de \(e\) ;
à ce moment là le parseur aura lu un autre caractère qui lui permettra de choisir
entre les alternatives \(NT1\) et \(NT2\).
Exercice 1
Modifiez la grammaire pour autoriser les états primés.
Exercice 2
Modifiez la grammaire pour autoriser l'absence de point-virgule ";" au dernier chemin avant "}" et permettre à l'utilisateur d'écrire AEF(A){ ->1 } au lieu d'exiger AEF(A){ ->1 ; }
Exercice 3
Modifiez la grammaire pour autoriser les couples (de couples)* d'états.
Vous aurez besoin de créer plusieurs non-terminaux pour distinguer les étapes dans la reconnaissance d'un état : au moins begin_state, end_state